BM25 is a popular search algorithm that finds documents related to queries based on weighted terms in queries and documents. The weights are determined by the frequency of the words in the dataset, and how frequently they occur in that particular query and document.
While there are several algorithsm used to make the BM25 algorithm more efficient, they are still mainly targeted towards single-threaded applications. In fact, most BM25 algorithms rely on a single-threaded technique called block-max WAND (BMW) to skip over large portions of the dataset that are guaranteed to not contain any documents that would be relevant to the query.
I'll quickly describe the algorithm:
- documents are grouped into chunks of k documents (some papers suggest you can set a variable block size within each posting list, while other suggest clustering algorithms)
- there is a vector generated across those documents (which you could call a summary) which takes the maximum value for each term across all the documents in the block and puts it into a single vector.
- when you have a query and a heap of documents (representing your current top-k), you can find the inner product of your query vector and your block's summary vector. If the inner product is less than the smallest score that you are keeping in your heap (or the k-th highest element you've seen so far), then it is guaranteed that none of the documents in that block are going to have a score high enough to be considered, so you can safely skip that block and all of the documents inside it.
The actual implementation is more involved, with pointers storing the current position in the posting list for each term in the query, and a lot of optimizations to make sure that the number of inner products that need you need to compute is minimized.
Here are a few of the papers that I read on lexical search algorithms, sparse vector retrieval, and similar topics that I thought were useful when trying to figure out how to design this paper:
- SPARe
- SPARe introduces an iterative algorithm for performing sparse vector search on GPU. Like other optimizations, it converts the BM25 algorithm into a sparse matrix-vector operation. In particular, it calculates term weights for each query and document and stored document data in the CSR and CSC data formats, which are sparse matrix formats designed to maximize the amount of memory coalescing involved in reads
- Then, it iteratively works through the terms of the query and accumulates the document scores in memory.
- After calculating all the weights, a simple top-k operation is performed.
- Methods like quantization can be used to reduce the amount of memory needed, and to reduce the amount of time spent on memory transfers.
- Efficient Inverted Indices for Approximate Retrieval over Learned Sparse Representations
- This paper introduces Seismic, which aims to improve the speed of retrieval for learned sparse representations (like the ones outputted by models like SPLADE).
- Learned sparse representations differ from the raw token data for a few different reasons:
- They have fewer unique terms, because of the way that tokenization works
- They have many more terms per document, because each term is augmented by the context of the document
- As a result, posting lists are significantly longer, and documents are less sparse.
- Learned sparse representations differ from the raw token data for a few different reasons:
- Seismic uses a the following approaches:
- First, the authors observed that in these learned sparse representations, they are able to significantly truncate the number of terms per document and query by only selecting the terms/documents with the highest weights, up to a given threshold. They call this subvector the "alpha-mass vector".
- Second, instead of ordering documents by document id, documents are grouped through a variant of k-means clustering, before the maximum is taken for each term to perform BlockMax WAND.
- Finally, since they use term-at-a-time retrieval, they retrieve individuals document vectors themselves when a particular block needs to be explored.
- They are able to achieve very high recall (>0.95) at high speedup ratios (3x), especially when compared to other approximate inverted index methods.
- This paper introduces Seismic, which aims to improve the speed of retrieval for learned sparse representations (like the ones outputted by models like SPLADE).
- Pairing Clustered Inverted Indices with kNN Graphs for Fast Approximate Retrieval over Learned Sparse Representations
- This paper introduces SeismicWave, which builds on top of Seismic to further improve the speed of retrieval.
- First, documents are processed in order of the similarity of their block summary vectors to the query vectors. This allows the algorithm to find high-scoring documents earlier, which allows for more blocks to be skipped later on.
- Second, in addition to reading each document vector when a block is explored, the algorithm also precomputes a kNN graph over all of the documents. When a document is found that has a high score, its neighbors in the kNN graph are also explored. This allows the algorithm to find more high-scoring documents earlier, which again allows for more blocks to be skipped later on.
- Bridging Dense and Sparse Vector Retrieval Methods
- Basically, this paper shows that you can use a random projection to convert your sparse vectors into dense vectors. Then, you can apply traditional clustering algorithms over your dense vectors and obtain high-quality results.
- One of the important results is that normalizing all of your centroid vectors (ie putting them on the unit sphere) makes your cluster matching significantly more effective. However, the method that you use to project your sparse vector into a dense vector doesn't matter that much, and using random vectors (where each element is selected from a Gaussian distribution) for each term is effective.
- Other sections discuss how combining projected sparse vectors and dense vectors can be effective in reducing the amount of complexity involved in performing hybrid search.
I wanted to explore some ideas that could make BM25 more efficient in a highly parallel setting. In addition, I wanted to be fast, even with a memory-mapped system so that this could be cheaply served from disk.
Ideas I Tried to Implement
- You can parallelize BM25 on a single machine by sharding across threads and then aggregating results.
- Especially when comparing and scoring sparse vectors, it could be more efficient and easier to convert the sparse vectors to a dense vector (through some sort of random projection), and then cluster / process the dense vectors.
- For a given document, you don't need to immediately score every term in the document (at least in the first stage pass). Instead, you can use a two-stage approach where you first stream in and aggregate term weights from the blocks that are most similar to the query, and then rerank the top-k documents using the full sparse vector.
- Using "alpha-mass" subvectors to truncate the number of terms in each document, like in Seismic.
Implementation and Benchmarking
Preprocessing
By preprocessing the dataset in a way that keeps similar documents together, if I am able to identify a good set of initial clusters, I could find a useful set of candidate documents to process. First, to reduce the amount of computation I have to perform for the clustering and during query time, I generated a random projection matrix to create a small dense vector for each document. Then, I form a set of dense clusters, and for each cluster, store a pair of Cluster { centroid: Vec<f32>, documents: Vec<(u32, f32)> } To do this, I implement a simple greedy algorithm where I select a document, find the k closest documents, and store that as an individual cluster. I do this repeatedly until there are no further remaining documents. In addition, I also average the values across the dimensions for the documents in the cluster and store that as a cluster vector. This will be compared against the queries later on to select which cluster should be evaluated in the first stage. Finally, to make splitting work across threads easier, I segment the document IDs into num_cluster_segments segments, and store the documents in each cluster segment according to their document_id. This turns my Cluster { centroid: Vec<f32>, documents: Vec<(u32, f32)> } pair for a given cluster into Segment { documents: Vec<(u32, f32)> }; SegmentedCluster { centroids: Vec<f32>, documents: Vec<Segment> }. Note that you only need to store the term weight for that document in each segment. Aggregation will happen later. A limitation that I have right now is that rkyv (the serialization library under mmap_sync, which I use to simplify mmapping) doesn't support large files, so I had to truncate my dataset for this test. In the future, I could split up data across several files. Another improvement that I implemented was a basic quantization algorithm that converted my f32 weights to u8 using the logarithm of the weights to make sure they were more evenly distributed.
First: projection and normalization
By using the same seeding variable to construct the projects both when indexing and when querying, we can make sure that the same vectors are used in both staging. In the future, if there are an extremely large number of terms, this could be done by some pseudo-random algorithm rather than generating the projection vectors and storing them. After projecting the query vector, I normalize it to find the weights of each term in the query. This determines how many clusters for each term are processed. Less important terms have fewer clusters processed, while more important terms have more clusters processed.
Second: cluster identification
Each term has a separate set of clusters that need to be processed and streamed. The top clusters are simply identified by taking the dot product of the projected query vector and the averaged document vectors in that block.
Third: streaming in data from the clusters
Each cluster consists of (document_id, term_weight) pairs. Using the cluster segments that we computed when forming the dataset, you can reorganize this into num_cluster_segments blocks. Retrieved documents should be evenly distributed across these cluster segments. This is another level of sharding, but across threads. As data from the clusters gets streamed into these individual buckets for each thread, they are stored in a heap sorted by the document id. Then, elements of the heap are processed in order of document ID (with scores aggregated for a certain document ID if they are presented in order) and stored in a second heap, sorted by document score. Then, the top-k from the second heap is returned by the thread and, once aggregated, resorted to get the final top-k.
Fourth: reranking documents
However, this approach can get the ranking of important document in an inaccurate way. For this, it's imperative to use a final stage reranker. This reranker is pretty simple: for each top document, the program pulls the sparse vector from a mmapped file and computes the true weight of the sparse vector-vector multiplication.
Because I wanted to see how this would perform when served from disk, I decided to write an mmap-ed implementation. My initial implementations were more complicated than necessary, as I tried to serialize the data myself in a custom format so that it would be easy to read from disk. While this was trivial for fixed-length vectors like the dense centroid vectors, it was far more complicated for the segmented clusters. After a bit of search, I stumbled upon the mmap_sync library from Cloudflare, which uses a zero-copy deserialization technique. With a zero copy approach, I didn't have to wait for all the data to be loaded into memory (with idle CPU time) before processing it. Furthermore, implementing with mmap_sync was much simpler than my implementations where I managed parts of the serialization myself.
As my baseline in Python, I used bm25s. bm25s has strong benchmark performance against other BM25/lexical search algorithm, and offers a mmapped version, which makes it much easier to perform a fairer comparison between their mmapped approach and my mmapped approach.
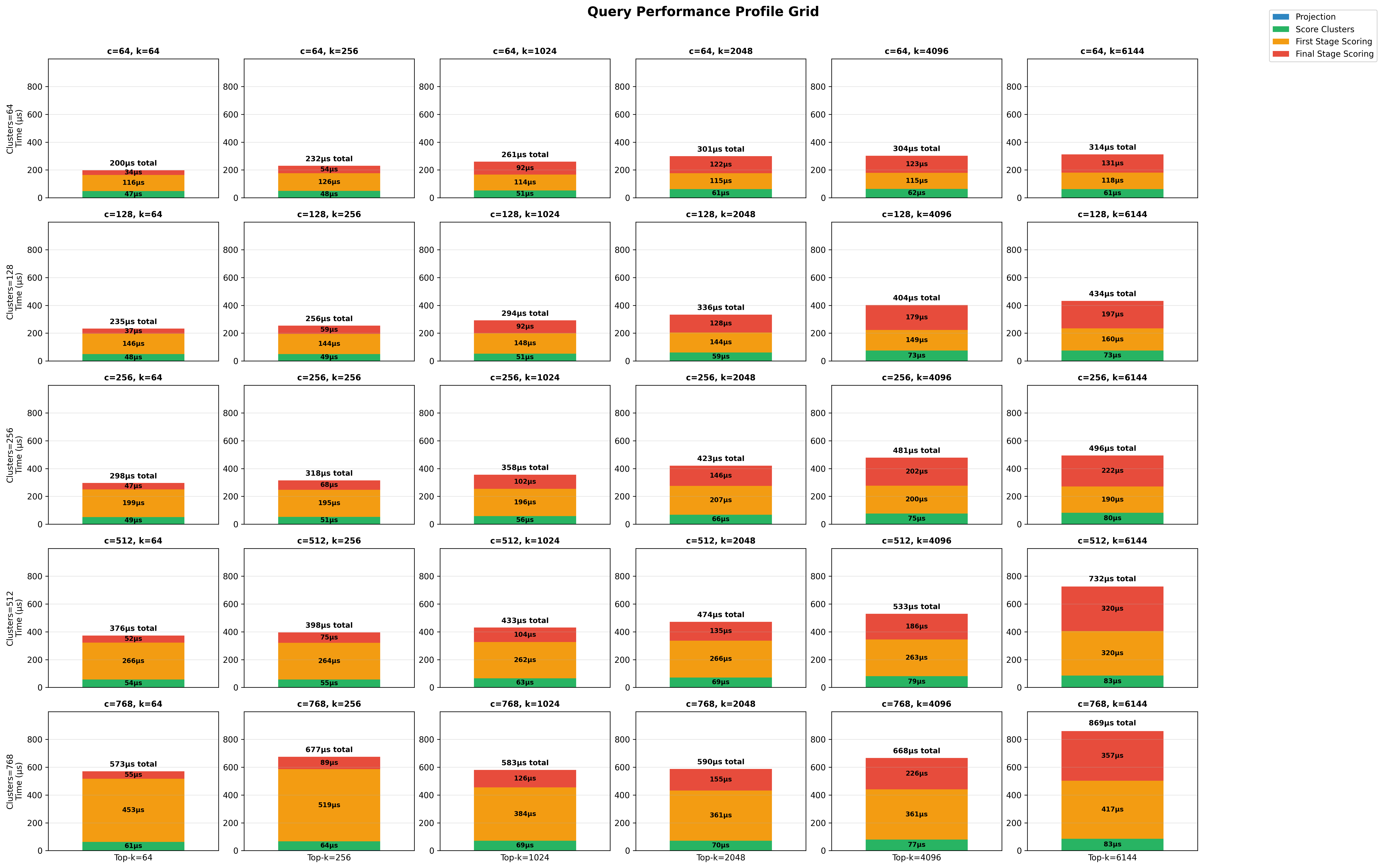
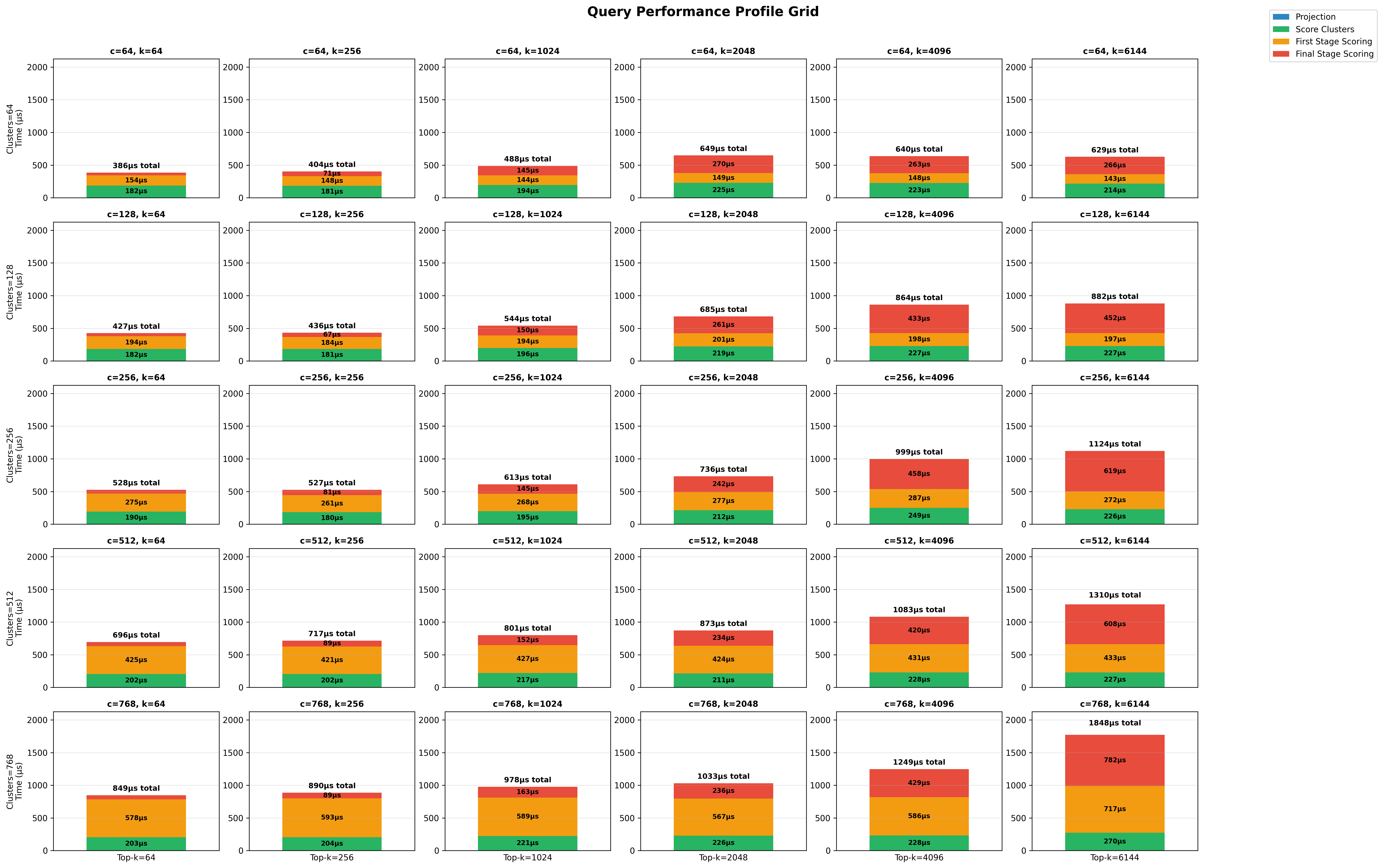
To understand the performance of my system, I started by trying to use the Rust flamegraph crate. My first several profiles showed that the Rust Rayon library was taking a ton of time, even when I set RAYON_NUM_THREADS=1 as an environment variable. I tried a few different approaches to trace the code that I had to see which spans of code were taking the most time, but to produce the graphs below, I used a custom implementation to store the data and save it in JSON so that I could more easily break it down and understand how latencies changed depending on different hyperparameters.
Specifically, I tested it against the Quora and Natural Questions datasets from BEIR. I evaluated performance on 768 queries, and for the Natural Questions dataset, I truncated the dataset to 1.5 million documents because of limitations with the rkyv library as mentioned previously. Other hyperparameters are described in the figure itself.
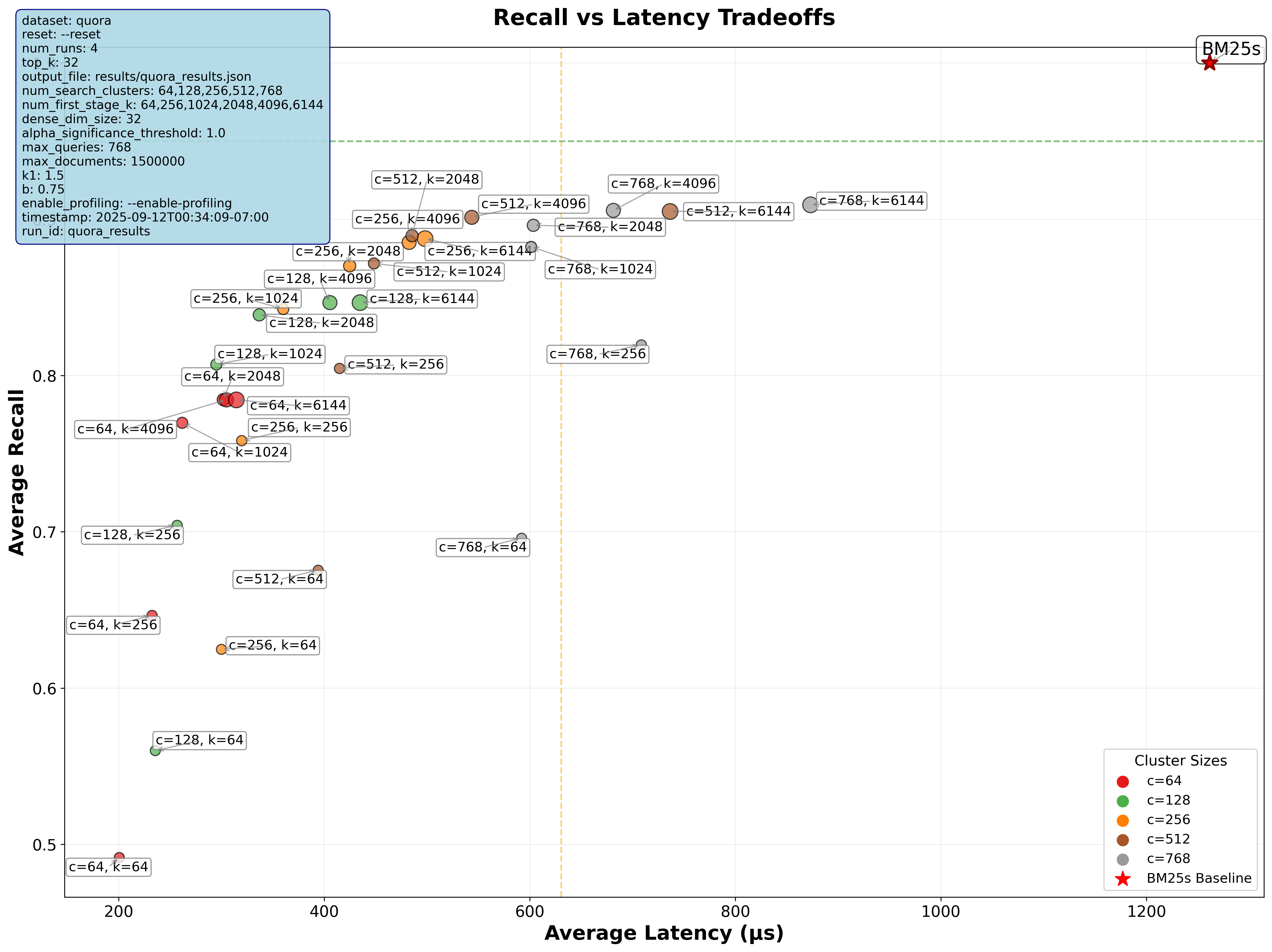
Accuracy vs. Speed Tradeoffs on the Quora dataset
Runtime Breakdown on the Quora dataset
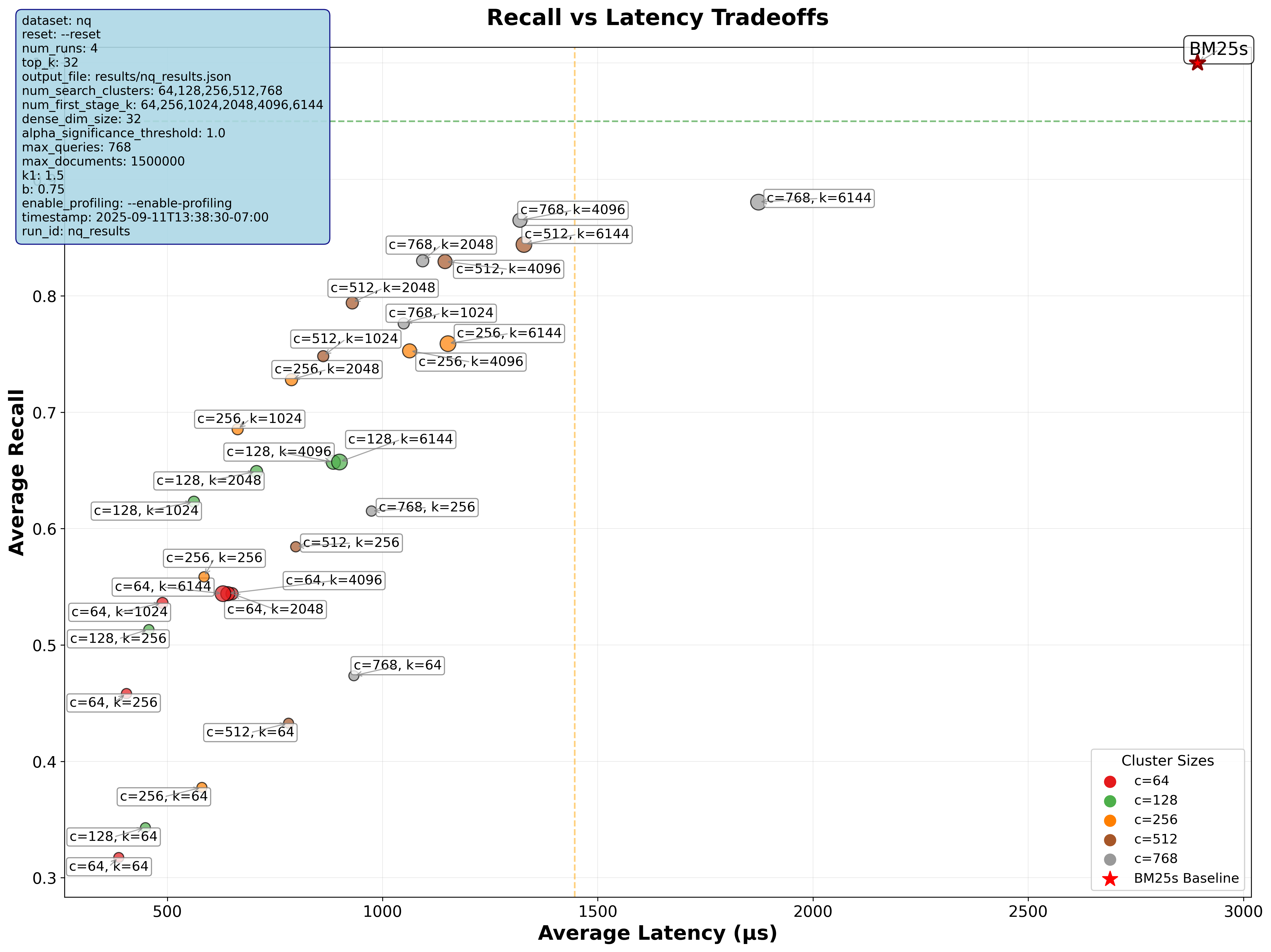
Accuracy vs. Speed Tradeoffs on the NQ dataset
Runtime Breakdown on the NQ dataset
As you can see, this method struggles to get a recall rate above 0.9, even when reranking a large number of documents.
Looking Forward
- One thing this lacks is a recall guarantee for a given query. For every distribution of queries, you would need to independently precompute how many clusters need to be traversed, and how many first stage documents need to be reranked to get an accurate top-k.
- One popular way to solve this would be to use the block-max approach. It would be interesting to see if using dense vectors for block-max scoring work well enough, in comparison to using the original sparse vector.
- I could start implementing parts of this on the GPU
- The projection, cluster weight scoring, and rescoring could all likely be implemented for the GPU with existing kernels.
- However, the first stage streaming, aggregation, and top-k selection would likely need to be implemented from scratch.
The code for this is on (GitHub)[https://github.com/vdaita/approximate-lexical]. Let me know if you have any suggestions!