Introduction
My friend recently sent me this blog post by Shengding Hu on efficient long-context models. One of the ideas introduced towards the end was that, it is not possible to maintain accuracy consistently while compressing data. This is clearly the case with linear transformers when working with an input consisting of a context and a question. The linear transformer has to compress the context before knowing what the question is, because of the decoder architecture. In fact, the Just Read Twice blog post shows that significant performance gains can be achieved by providing this kind of context twice, allowing the model to prime itself to focus only on the relevant information. To keep inference costs slow, Hu proposes moving some of the key-value (KV) cache onto a cheaper, slower memory (i.e. HDD), and only loading specific blocks when they are required. Now, calculating which blocks are relevant for each token while decoding would make the model prohibitively slow, as instead of a simple matrix-vector calculation for each attention layer and each token, a model would have to first calculate which blocks are important, load those into memory, and then perform the actual attention computation itself. If the cost of figuring out which blocks are important and loading them in could be amortized over several tokens, the speed-up on a faster matrix-vector computation could make up for the time taken to calculate important blocks. Hu proposed a system that combines linear attention and regular attention to achieve this.
Native Sparse Attention works by training a model from scratch, and breaking attention into 3 parts: one that uses compressed vectors for each block across all blocks in the input, another (based on block-sparsity) to identify the most relevant KV blocks for each query vector, and another that uses a sliding window for recent information. While this achieves significant gains in the time spent for decoding, there is still a lot of high-bandwidth memory usage required because large KV caches must be maintained and quick to access.
I wrote a blog post earlier that evaluated different training free methods of finding which KV blocks represented most of the attention weight for which query blocks. In particular, I explored different strategies for aggregating query and key vectors across a block to facilitate this. This is useful for the prefill stage, when all of the text is visible at the same time.
Here, I wanted to test what would happen if the aggregated vector for a given block was just the query vector representing the first token. Current approaches to make decoding for standard transformers more efficient involve some form of KV cache compression or truncation, where based on the input, part of the information is completely discarded. A couple clear examples of this potentially causing issues are long generations that may cover several topics and multi-turn conversations. If the attention map of the first token is representative of the attention map for the entire block, then that means that new key-value blocks can be loaded into high-bandwidth memory at the start of each block, and other KV blocks can be stored in slower, cheaper storage rather than being discarded completely. Since the cost of calculating the attention map first and loading those relevant blocks is only there for the first token in the block, the time that takes can be amortized over all of the tokens generated in that block. Furthermore, it could mean that many existing strategies used to optimize model prefill with block-sparsity could be adapted to optimize the model decoding stage.
Methodology
Compared to my previous blog post, I switched to an L4 system on Lightning AI rather than the university-provided A100s. To deal with this, I switched to a shorter dataset, both in the number of examples and the length of the text used to avoid running out of memory. I implemented the "first-token" strategy, where for the queries, the first token of the block is selected and for the keys, the vectors are averaged over the whole block. To generate the graph of cumulative attention coverage, I computed the original attention maps and then aggregated scores at the block level.
Results
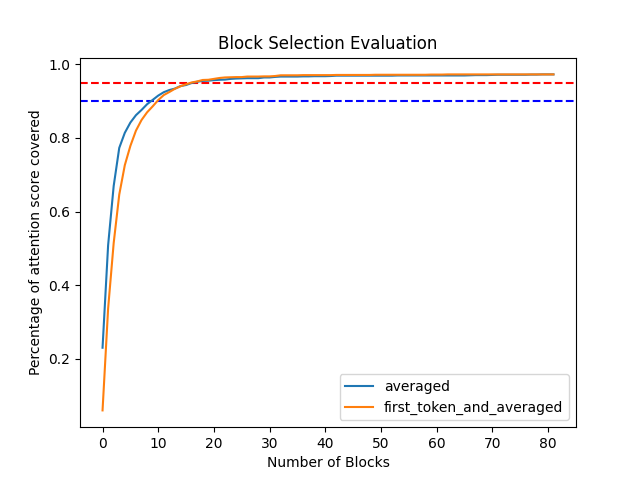

While the ‘first_token_and_averaged’ method lags in reaching 90% attention coverage, it outperforms the averaged method in reaching 95%. Saving most of the KV cache to a slower memory (such as standard RAM or SSD), and retrieving blocks based on the top-k blocks retrieved by the first vector could be an effective and efficient way to handle generating text across long sequences while reducing the amount of HBM that needs to be used at any given time.
The code for this can be found on GitHub: vdaita/block-selection-eval.