Retrieval-augmented generation (RAG) is commonly used in LLM pipelines to gather relevant information and context to feed into a model (local or flagship). Usually, this involves taking the user's query, using a text embedding model to produce a vector for the query, and finding the most relevant embedded documents from the vectorstore by using the cosine similarity metric.
Sometimes, a reranker is added at the end. Instead of embedding the question and the documents separately and finding which document vectors are closest to the question vector, a reranker takes in the documents and the question at the same time and produces a ranking of which documents are most relevant to answering the question.
Another method for dealing with long contexts is to dump it all into the model's context window. New models, like Gemini, are coming out with million-token context windows. However, benchmarks like RULER and InfiniteBench show performance degradations for complex tasks beyond a short context window.
The alternative is token-compression technique, which analyze the text and try to compress on a token level. The LLMLingua series proposes several techniques to remove irrelevant tokens. It works by using a standard decoder model (such as Mistral-7b) to calculate which tokens have the lowest perplexity.
LLMLingua-2 works by training an encoder model (such as BERT) with a token classification head to classify each token in the text as important or unimportant. The dataset used to train this is generated by GPT-4 and relies on carefully prompting GPT-4 to produce an extractive summary, and then post-processing it in an adaptable way to present a token classification result.
However, both of the aforementioned techniques do not take into consideration whichever query the user might be making. Knowing what the query is could lead to better and more accurate compression.
EFPC (Efficient and Flexible Prompt Compression) does that by adjusting the dataset for LLMLingua to include questions. Instead of the teacher LLM compressing the entire text, with EFPC, the LLM instead compressed the entire text down to tokens that are relevant for answering a single question.
CPC (Context-aware Prompt Compression) works differently. Instead of compressing at a token level, CPC compresses at a sequence level. In some ways, it works similarly to a reranker to determine which sentences (or small chunks) are the best to consider. However, in a reranker model, only a given document and a given query can "see" each other. In CPC, each chunk gets the context of the chunks around it because the entire document is processed as one, while chunking and ranking happens later. For this, a training dataset is sythetically generated by a LLM model, which generates question-answer pairs given a piece of text and then classifies whether a sentence or chunk of text is sufficient to answer a given question. The student model (which is to operate in a single forward pass) is trained on these pairs, combined into a single large context window.
I wanted to try and compare a few different strategies modifying and combining token-based compression (with LLMLingua2) and chunk-based compression (with CPC). For both of these, I used the small variants of the trained models.
-
Baseline LLMLingua
-
Baseline CPC
-
Sequential CPC
Right now, the text is chunked into larger chunks before being processed by the model. This chunking happens independently. What would happen if you compressed the first chunk, and added it to the start of the second chunk, and so on? Would that produce better results?
-
CPC -> LLMLingua What if you identify the important blocks of text with CPC first (with a higher token budget), and then use LLMLingua to remove the most irrelevant tokens within the relevant chunks? Uses double the budget for CPC, and then compresses to meet budget with LLMLingua.
-
Sequential CPC -> LLMLingua To validate these strategies, I used a subset of the NarrativeQA task in LongBench where the number of words was between 5000 and 10000 and evaluated the F1 score of the model's output. The compressed context was then passed to gpt-4.1-mini.
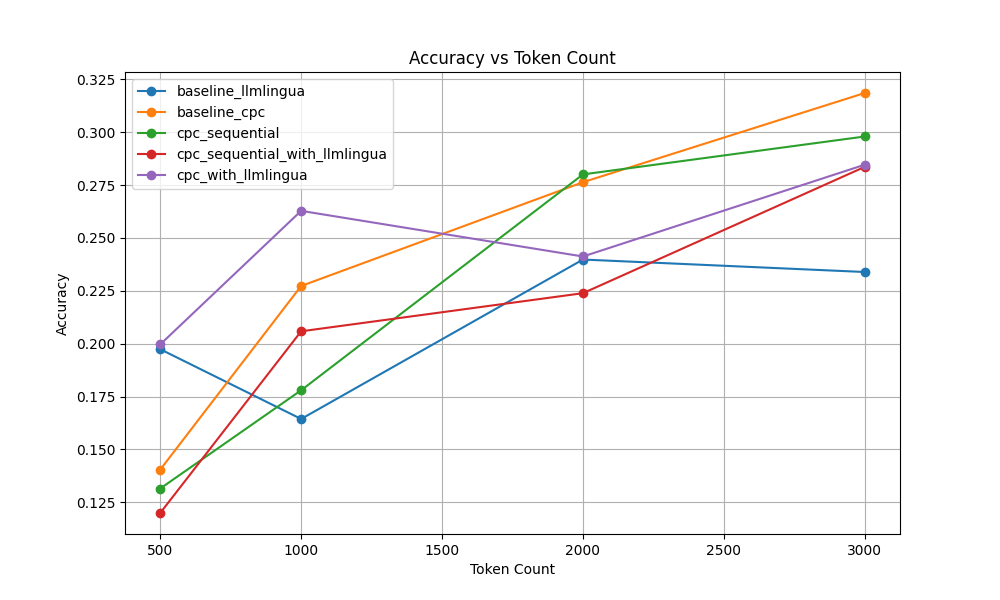 Most of the graphing code was one-shotted by Claude.
Most of the graphing code was one-shotted by Claude.
These results show that the "sequential" approach doesn't achieve any significant performance improvement. However, it does show that token-based compression techniques overperform chunk-based approaches when there is a greater budget constraint. When the token budget is 1000, where using CPC with LLMLingua significnantly outperforms the normal CPC model. When the token budget if 500, both baseline LLMLingua and CPC with LLMLingua have similar performance and notably significantly outperform the chunk-based approach. The results in the graph suggest that manually tuning how compression is split could lead to performance gains.
You can see my modified version of the CPC repo at vdaita/qatc. Please email me if you have any feedback!